시퀀스 데이터(Sequential data)
특정 원소의 순서가 있는 시퀀스 원소는 상호 독립적이지 않다.
일반적인 지도학습을 위한 머신 러닝 알고리즘은 입력 데이터가 독립 동일 분포(Independent and Identially Distributed, IID)라고 가정한다.
IID 데이터들은 상호 독립(mutually independent)적이고 같은 분포에 속한다. 따라서 모델에 전달되는 훈련 샘플의 순서는 관계가 없다.
시퀀스의 경우 독립 동일 분포 가정이 성립하지 않는다.
주식 시장의 가격을 예측하는 경우, 날짜를 랜덤하게 데이터를 훈련시키는 것이 아닌 날짜 순서대로 정렬된 이전 주식 가격을 고려하여
트렌드를 감지해야 한다.
순차 데이터 & 시계열 데이터
시계열 데이터는 순차 데이터의 특별한 한 종류이다.
시계열 데이터는 각 샘플이 시간 차원에 연관이 있으며, 연속적인 타임스탬프를 따라 샘플을 얻는다.
시간 차원이 데이터 포인트 사이의 순서를 결정한다.
ex) 주식 가격, 녹화된 음성, 대화
텍스트나 DNA 시퀀스는 샘플이 순서를 가지지만, 시계열 데이터로 볼 수는 없다.
자연어 처리(Natural Language Processing, NLP)와 텍스트 모델링은 시계열 데이터는 아니다.
RNN은 시계열 데이터에 사용 가능
Sequence
MLP(다층 퍼셉트론), CNN(합성 신경망) 모델의 경우 훈련 샘플이 서로 독립적이어서 순서 정보와 연관이 없다고 가정한다.
(이전에 본 훈련 샘플을 기억하는 메로리가 없다: 샘플이 정방향 계산과 역전파 단계를 통과하면
가중치는 훈련 샘플의 처리 순서에 상관없이 독립적으로 업데이트 된다.)
RNN의 경우 시퀀스 모델링을 위해 고안되었으며, 과거 정보를 기억하고 이에 맞춰서 새로운 샘플을 처리한다.
Sequence Models
시퀀스 모델링에는 언어번역(ex 영어 텍스트 독어로 번역), 이미지 캡셔닝(captioning), 텍스트 생성 등에 많이 사용된다.
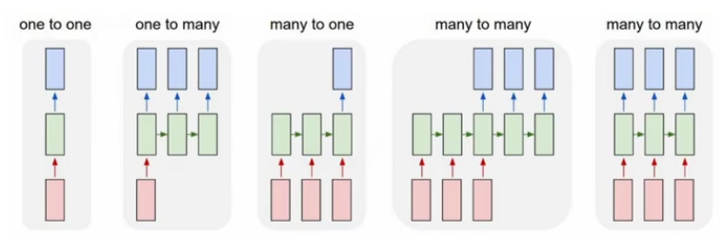
많이 사용되는 모델
다대일(many-to-one)
입력 데이터가 시퀀스 이지만, 출력은 시퀀스가 아니고 고정된 크기의 벡터나 스칼라이다.
예를 들어 감정 분석에서 입력은 텍스트이고 출력은 클래스 레이블이다.
일대다(one-to-many)
입력 데이터가 시퀀스가 아니고 일반적인 형태이고 출력은 시퀀스이다.
예를 들어 이미지 캡셔닝의 경우 입력은 이미지이고 출력은 이미지 내용을 요약한 영어 문장이다.
다대다(many-to-many)
입력과 출력 배열이 모두 시퀀스이다.
입력과 출력이 동기적인지의 여부에 따라서 추가적으로 나누어 지며,
동기적인 다대다 모델링은 예로 각 프레임을 레이블링하는 비디어 분류
지연이 있는 다대다 모델의 예는 한 언어를 다른 언어로 번역하는 작업이 있다.